前言
完整实现
完整实现已上传代码仓库:wdl339/chfs。
参考资料
非常感谢助教们的及时耐心的答疑,以及我见过最好的作业文档(从CSE | Fall 2024 | Schedule获取)。本博客基本沿用了作业文档的框架,不同之处在于现在是站在已经完成后的视角,而非正在做作业时候的视角。
获取源代码
| |
(这里url换成https://ipads.se.sjtu.edu.cn:1312/lab/cse-2024-fall.git的话,就是最初始lab1的作业框架)
更改目录权限。以下命令用于授予目录chfs内所有文件和目录的写入(w)权限给其他用户(o),并且递归(-R)操作。
| |
在chfs目录下,获取git子模块:
| |
环境配置
我们使用docker容器来完成所有的实验,并且我们提供了一个包含这些实验所需所有环境的容器镜像,这将简化环境的配置。
要获取docker镜像,你有两种选择:
- 从远程仓库拉取:
1 2 3docker pull registry.cn-shenzhen.aliyuncs.com/cse-lab/cse-lab:v1 docker tag registry.cn-shenzhen.aliyuncs.com/cse-lab/cse-lab:v1 chfs_image- 在本地构建docker镜像。在
chfs目录内执行以下命令:
1docker build -t chfs_image .创建一个docker容器。如果你没有删除容器,你只需要创建一次docker容器。在
chfs目录内执行以下命令。以下命令将chfs目录挂载到docker容器,这意味着目录内文件的所有更改都会反映在docker容器内,反之亦然。
| |
- 启动docker容器:
| |
- 现在就已经在docker容器内,它应该看起来像这样:
| |
- 用户名是
stu,密码是000。 - 可以在容器外编写代码,但必须在容器内编译代码并执行测试脚本。
- 可以在容器内输入
exit命令或按下Ctrl+D来停止容器,然后将返回到宿主机的shell。下次不要忘记启动容器。 - 可以使用vscode并安装
Dev Containers扩展,以便在docker容器内方便地开发。
Basic Filesystem
概览
架构
这部分内容是实现一个单机(多线程)的基于inode的文件系统。以下是文件系统的架构:
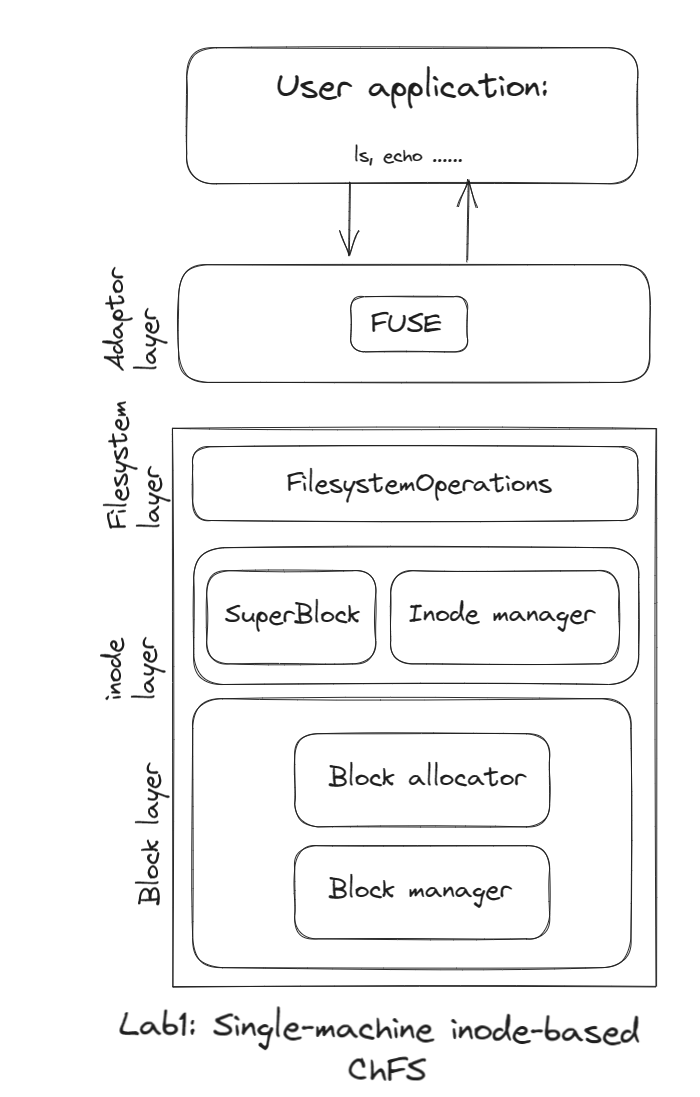
文件系统由三层组成:block 层、inode层和filesystem层。
block 层提供用于分配/释放block以及从block中读取/写入数据的API。
inode层以inode的形式管理block层提供的block。这一层提供了用于分配/释放inode以及从这些inode中读取/写入数据的API。superblock也位于这一层,它记录了文件系统的一些关键信息。
filesystem层提供了一些基本的文件系统API,包括文件操作API和目录操作API。
此外,为了让其他用户应用程序真正使用文件系统,还有一个Adaptor层。它是用户应用程序发出的标准文件系统请求(例如ls、echo命令)与文件系统对应操作之间的翻译器。
编译
在容器内,进入chfs目录,并执行以下命令:
| |
测试
运行单元测试,在build目录下执行以下命令:
| |
注意:如果测试过程中出错,可能会留下一些中间状态的文件系统数据。这会导致下一次运行测试时,环境不是完全清空的状态,从而可能导致测试失败。中间状态会保存在容器的 /tmp 目录中。在容器里执行 make clean-fs 来清理这些中间状态,不需要重新编译。
集成测试将挂载文件系统,并执行一些真实的文件系统操作,如ls、echo等。要运行集成测试,首先编译Adaptor层,在build目录下执行以下命令:
| |
然后在scripts/lab1目录下执行以下命令:
| |
Demo
在chfs目录下,执行:
| |
脚本返回后,chfs目录内会出现一个mnt目录。进入mnt目录。CHFS文件系统已挂载到此目录,这意味着此目录内的每个文件系统请求都将CHFS来完成。
创建一个新目录:
| |
在该目录内创建一个新文件:
| |
检查是否成功创建了文件:
| |
向该文件写入内容:
| |
读取文件,看到刚才写入的内容:
| |
删除文件:
| |
删除目录:
| |
然后你会看到输出:
| |
这是因为当前这个文件系统不支持删除目录。如果你感兴趣,可以参考daemons/single_node_fs/main.cc中的chfs_rmdir并实现它。
Block层
Block层实现了块设备,提供分配/释放block以及从block中读取/写入数据的API。
Block Manager
在src/block/manager.cc中:
write_block:将一个block写入内部块设备。write_partial_block:将一个部分block写入块设备,提供block中写入内容的偏移量和长度。1 2 3 4 5auto BlockManager::write_partial_block(block_id_t block_id, const u8 *data, usize offset, usize len) -> ChfsNullResult { memcpy(this->block_data + block_id * this->block_sz + offset, data, len); return KNullOk; }zero_block:清除一个block的内容。read_block:将block内容读入缓冲区。1 2 3 4auto BlockManager::read_block(block_id_t block_id, u8 *data) -> ChfsNullResult { memcpy(data, this->block_data + block_id * this->block_sz, this->block_sz); return KNullOk; }
以下这段代码是在分布式的测试的时候使用,当maybe_failed == true,write_block会每三次固定失败一次,这会使一些操作(如mknode必然失败):
| |
Block Allocator
Block分配器使用bitmap来管理block的分配和释放。bitmap存储在某些block中。src/include/common/bitmap.h包含了操作bitmap的API。
在src/block/allocator.cc中:
allocate:分配一个block。先到bitmap中查找free bit,将其设为1,将改变的bitmap对应的block刷新(flush),根据free bit位置计算并返回block id。deallocate:释放一个block。修改对应bitmap并刷新。
Inode层
Inode层以inode的形式管理Block层提供的block。这一层提供了用于分配/释放inode以及从这些inode中读取/写入数据的API。Superblock也位于这一层,它记录了文件系统的一些关键信息。
Inode的结构在src/include/metadata/inode.h和src/metadata/inode.cc中实现。一个inode的布局正好fit一个block。Inode结构有点像多级页表,除开基本信息之外,就是一条一条的block id的条目。CHFS中最多只有一个double indirect block(最后一个条目)。
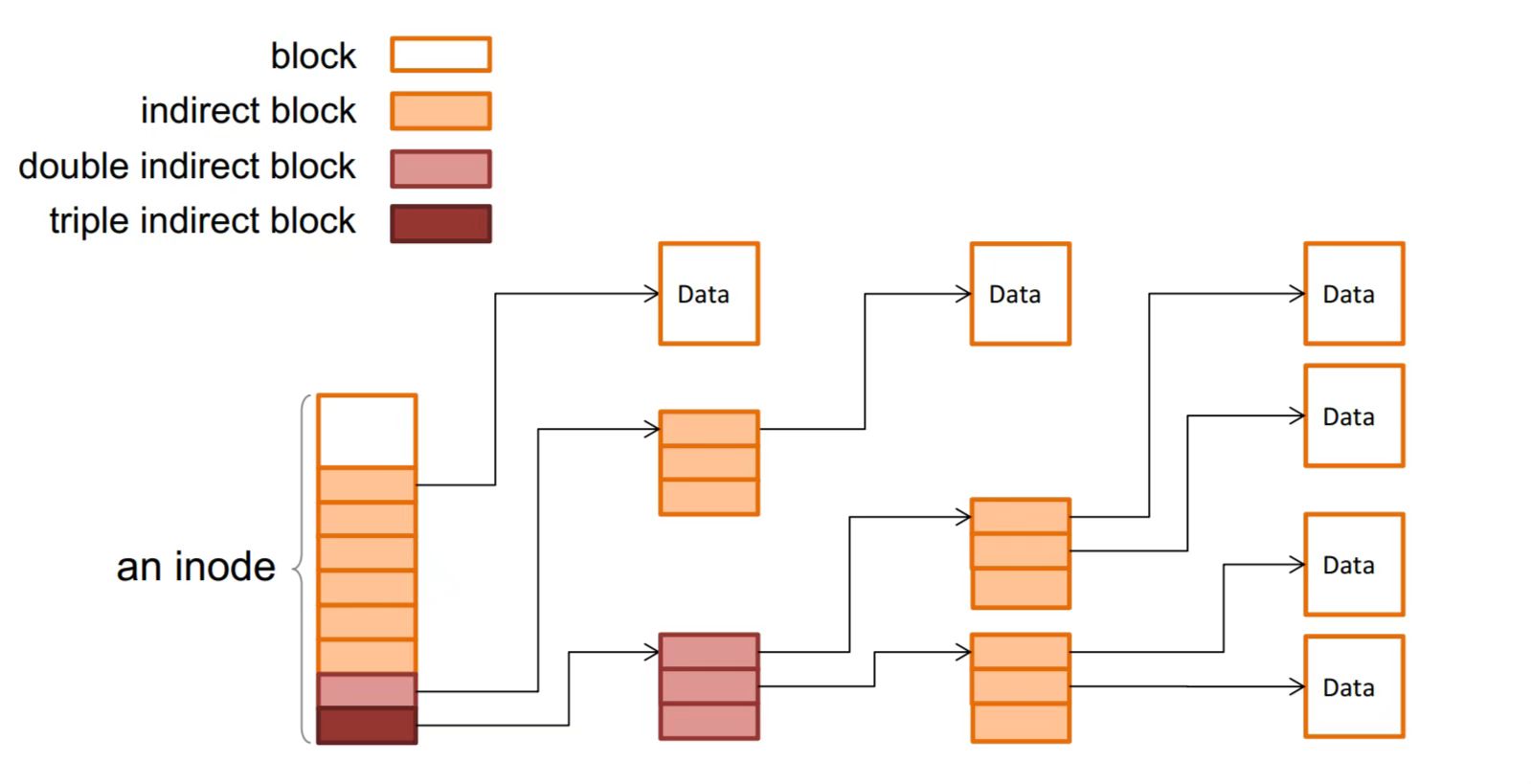
Inode管理器假设块设备上的布局如下:
| |
Inode Table是inode_id到block_id的映射, 这与直接存储inode的类不同。它将有更高的块利用率,代价是查找inode时的一次额外查找。block_id是实际存储Inode的块。首先读取相应的Inode Table块,然后获取block_id,然后通过这个block_id读取实际的Inode结构。Inode allocation bitmap用于指示每个Inode的使用情况。如果一个inode被占用,bit被设置为1。Block allocation bitmap用于指示每个Block的使用情况。如果一个block被分配,bit被设置为1。Other data blocks包含通过BlockAllocator分配的其他块。
给定一个inode的id,要了解它在Inode表中的索引(反之亦然),使用的是src/metadata/manager.cc中的宏RAW_2_LOGIC和LOGIC_2_RAW。
在src/metadata/manager.cc中:
allocate_inode:这个函数接受inode的block id,因为这个函数假设inode所在的块已经分配好了。- 分配一个inode,设置inode bitmap。
1 2 3 4 5 6 7 8 9 10 11 12 13auto iter_res = BlockIterator::create(this->bm.get(), 1 + n_table_blocks, 1 + n_table_blocks + n_bitmap_blocks); for (auto iter = iter_res.unwrap(); ...) { auto data = iter.unsafe_get_value_ptr<u8>(); auto bitmap = Bitmap(data, bm->block_size()); auto free_idx = bitmap.find_first_free(); if (free_idx) { bitmap.set(free_idx.value()); auto res = iter.flush_cur_block(); ... } }- 用特定类型初始化inode,设置inode table,返回inode id。
1 2 3 4Inode inode(type, bm->block_size()); auto inode_id = count * bm->block_size() * KBitsPerByte + free_idx.value(); bm->write_block(bid, reinterpret_cast<u8 *>(&inode)); set_table(inode_id, bid);free_inode:释放一个inode。设置inode bitmap和inode table。get:获取当前inode所在的块的block id。set_table:在Inode表中设置一个inode的block id。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22auto InodeManager::set_table(inode_id_t idx, block_id_t bid) -> ChfsNullResult { auto inode_per_block = bm->block_size() / sizeof(block_id_t); auto block_id = 1 + idx / inode_per_block; auto offset = idx % inode_per_block; auto buffer = std::vector<u8>(bm->block_size(), 0); auto res = bm->read_block(block_id, buffer.data()); if (res.is_err()) { return ChfsNullResult(res.unwrap_error()); } auto table = reinterpret_cast<block_id_t *>(buffer.data()); table[offset] = bid; auto res2 = bm->write_block(block_id, buffer.data()); if (res2.is_err()) { return ChfsNullResult(res2.unwrap_error()); } return KNullOk; }
Filesystem层
文件系统层提供了一些基本的文件系统API,包括文件操作API和目录操作API。
初始化
| |
这里可以看到CHFS是如何组织起以下这个布局的:
| |
InodeManager根据max_inode_supported,计算出n_table_blocks和n_bitmap_blocks这两个成员,对应| Inode Table | Inode allocation bitmap |。
BlockAllocator能看到的部分是| Block allocation bitmap | Other data blocks |,前面的部分属于reserved_blocks,前面已经确定大概占多少block了。
文件操作
在src/filesystem/data_op.cc中:
alloc_inode:先(Block Allocator)为inode分配一个block,再(Inode Manager)分配一个inode。这是文件系统层的create文件操作。read_file:读取一个inode的block内容。按照inode结构图,读取并拼凑data得到完整的内容。write_file:写入一个inode的block。注意可能由于内容的增减,需要动态分配/释放block并改变Inode和indirect block的内容。
目录项操作
在src/filesystem/directory_op.cc中:
parse_directory:解析目录的内容为条目并存储在列表中。read_directory:给定目录的inode id,读取其内容并解析为条目。append_to_directory:给定目录的内容,将一个新的filename->inode_id条目追加到内容中。rm_from_directory:给定目录的内容,通过给定的文件名从内容中移除一个条目。
目录和文件结合
在src/filesystem/directory_op.cc中,这些函数操作目录内的文件:
lookup:给定文件名及其父目录的inode id,返回文件的inode id。调用read_directory然后遍历即可。mk_helper:给定文件名及其父目录的inode id,在父目录内创建目录或文件。修改directory并调用alloc_inode。unlink:给定文件/目录的名称,从其父目录中移除它并释放其block。
Adaptor层
Adaptor层作为用户应用程序发出的标准文件系统请求(例如ls、echo命令)与文件系统对应操作之间的翻译器。它将拦截这些请求并将它们传递到文件系统实现中的适当函数。这个适配器层确保文件系统无缝集成到现有的操作系统基础设施中,允许应用程序与文件和目录交互,就像与其他任何文件系统一样。
CHFS使用FUSE(Filesystem in Userspace)提供的libfuse用户空间库来实现Adaptor层。在daemons/single_node_fs/main.cc中一些重要的函数(顾名思义即可):
chfs_openchfs_getattrchfs_readdirchfs_readchfs_mknodchfs_mkdirchfs_unlinkchfs_writechfs_setattrchfs_lookup
Distributed FileSystem
概览
架构
基于单机文件系统实现一个分布式文件系统。整体架构如下所示:
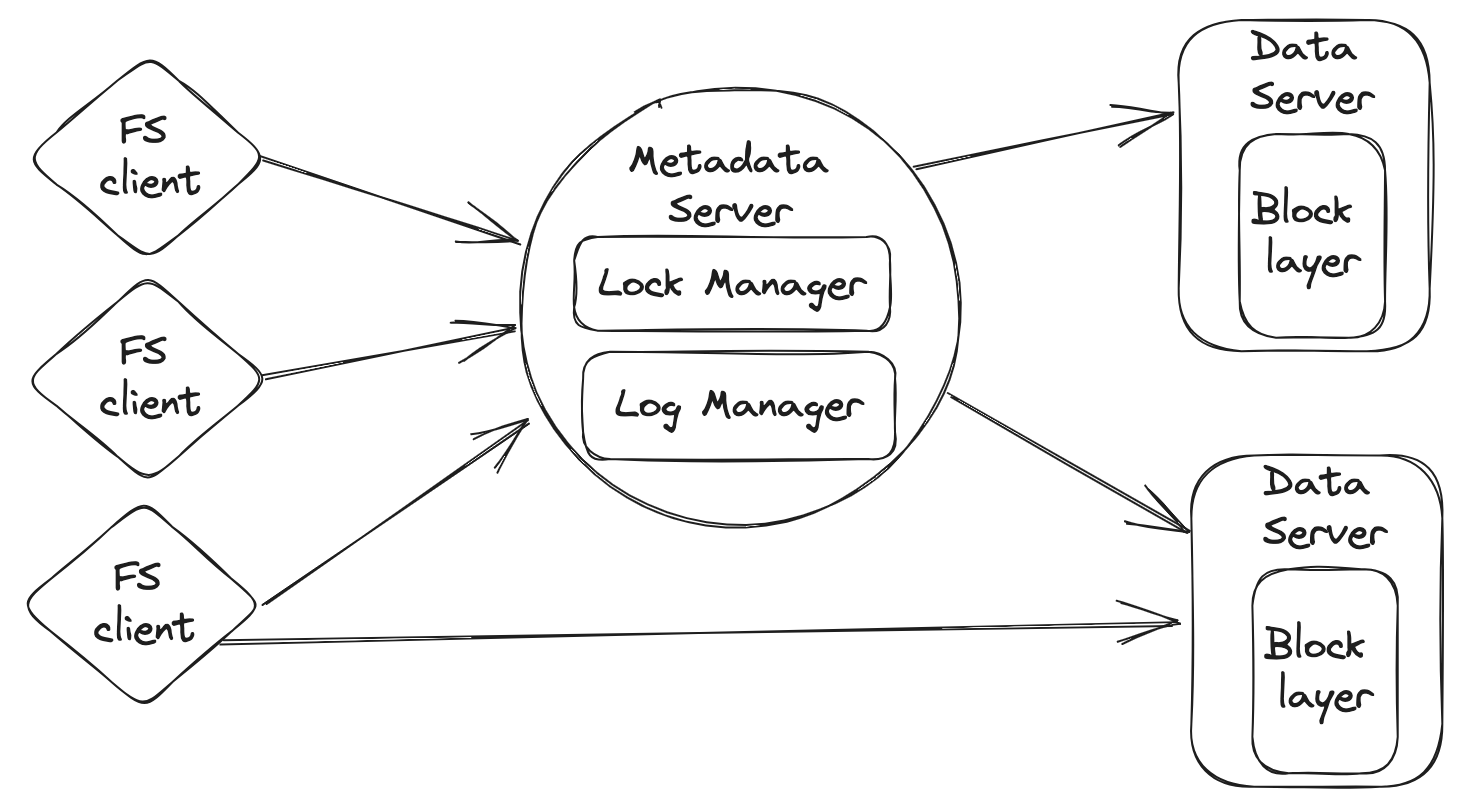
这个文件系统由三个部分组成:filesystem client、metadata server和data server。
一个文件被分割成一个或多个块,这些块存储在一组data server上。文件系统负责处理来自filesystem client的读写请求,以及来自metadata server的块创建和删除指令。
metadata server是一个维护所有文件系统元数据的服务器。它存储文件的inode和其他元数据,例如每个块的位置(机器ID)以及该机器上的block_id。此外,它还负责处理文件创建、删除以及查询读写数据块位置等元数据操作。CHFS只有一个metadata server(没有备份)。
filesystem client通过向metadata server和data server发出RPC来实现文件系统逻辑。
环境配置
Demo和集成测试与之前略有不同,要使用docker compose来设置环境。
要启动环境,在scripts/lab2目录下执行以下命令:
| |
完成后,所有容器将启动并初始化。可以使用docker ps检查容器的状态。然后打开另一个shell并执行以下命令进入挂载文件系统的容器:
| |
挂载点在lab2-fs_client-1容器中的/tmp/mnt目录。文件系统已挂载到此目录,这意味着此目录内的每个文件系统请求都将由你实现的文件系统来完成。
Demo流程与单机类似。
测试
测试包括三个部分:
- 单元测试
- 压力测试
- 集成测试
首先,在build目录下执行以下命令编译代码:
| |
对于单元测试,在build目录下执行以下命令:
| |
对于压力测试,在build目录下执行以下命令:
| |
对于集成测试,在lab2-fs_client-1容器中的scripts/lab2目录下执行以下命令:
| |
注意1:如果主机操作系统是Windows,在运行集成测试之前,可能需要在scripts目录下执行以下命令:
| |
此脚本将把scripts目录下的所有脚本从CRLF转换为LF,以便在Linux上运行。
注意2:运行集成测试后,无论结果是通过还是失败,都需要执行以下命令:
| |
此命令将删除docker compose up创建的所有容器。 下次运行集成测试时,你需要再次执行docker compose up,以便文件系统从空状态开始测试。
RPC
这些组件通过使用RPC(Remote Procedure Call,远程过程调用)相互通信。假设RPC不会失败。
LibRPC是chfs中的RPC模块。它遵循服务器-客户端模式。服务器设置函数处理程序并接收客户端发送的请求。
服务器
相关代码:src/include/librpc/server.h和src/librpc/server.cc
RPC服务器维护一个函数绑定的注册表,用于分发RPC调用。它在给定的地址和端口上监听,以建立连接和接收请求。
客户端
相关代码:src/include/librpc/client.h和src/librpc/client.cc
RPC客户端连接到特定的RPC服务器。它可以调用RPC服务器上的RPC处理程序。
基本上,RPC客户端支持两种调用方式:同步或异步。在同步方式中,客户端将等待请求完成。RPC调用的返回值是RpcResponse,可以将其视为一个字节列表。需要调用函数将其转换为你想要的内容。示例如下:
| |
在异步方式中,客户端将立即返回。它返回一个std::future,以便稍后获取结果。示例如下:
| |
Distributed filesystem
Data Server
在src/distributed/dataserver.cc中:
read_data:从块设备中读取块中的一段数据,提供块的偏移量和长度。write_data:将部分块写入块设备,提供块中写入内容的偏移量和长度。alloc_block:创建一个空块。free_block:清除一个块的内容。
本质上还是调用block manager或allocator里的方法。与单机的区别是,它们是远程调用。
Metadata Server
Metadata Server的块布局:
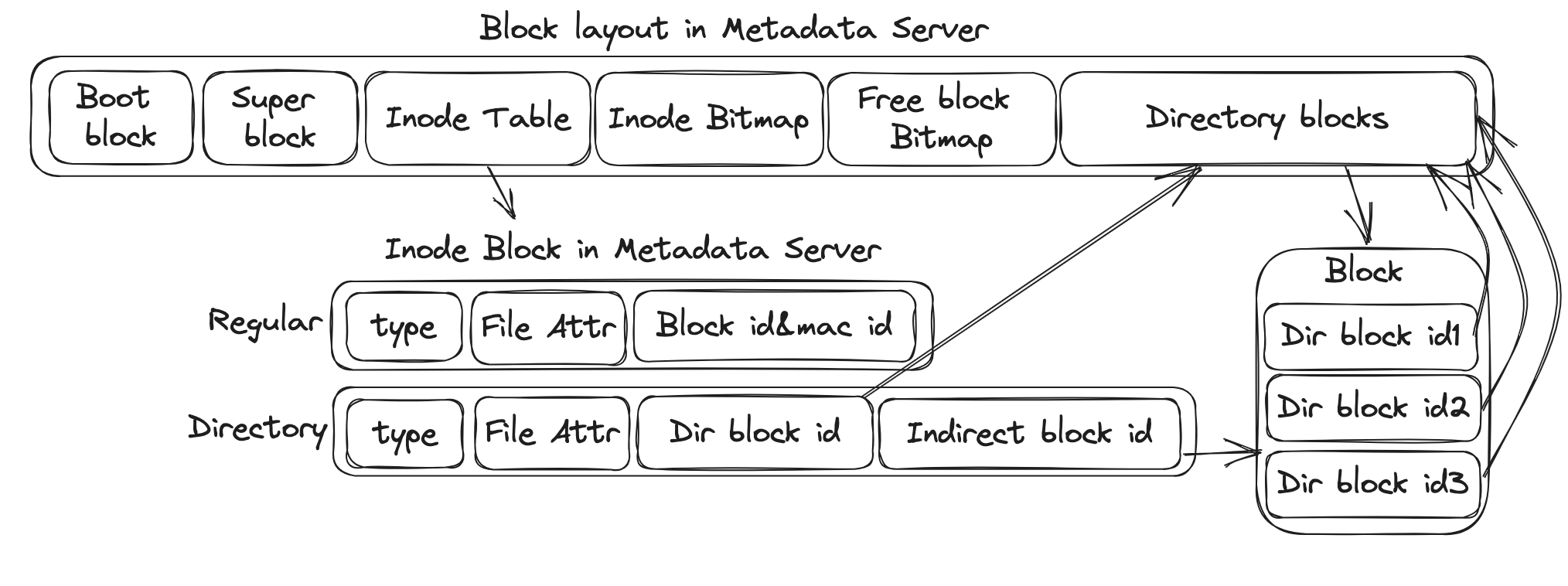
对于目录inode,它保存其所有直接和间接块ID,类似于单机。对于文件inode,它保存其所有块的映射(机器id和机器上的block id)。
在src/distributed/metadata_server.cc中(大多数函数的实现与单机几乎相同):
mknode:用给定的类型、名称和父目录创建一个inode。unlink:从其父目录中删除一个文件。lookup:尝试通过其名称和父目录搜索一个inode。readdir:读取目录的内容。get_block_map:返回inode的块映射。它包含每个块的块ID和机器ID。对于每个块,此函数还将返回其版本号。get_type_attr:获取inode的类型和属性。allocate_block:为文件分配一个块,以便客户端可以将数据写入该块。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51auto MetadataServer::allocate_block(inode_id_t id) -> BlockInfo { auto bm = this->operation_->block_manager_; usize block_size = bm->block_size(); std::vector<u8> inode(block_size); auto inode_p = reinterpret_cast<Inode *>(inode.data()); fo_mtx.lock(); auto read_res = this->operation_->inode_manager_->read_inode(id, inode); if (read_res.is_err()) { return {}; } auto inode_id = read_res.unwrap(); block_id_t block_id = 0; mac_id_t mac_id = 0; version_t version_id = 0; mac_id_t generated_id = generator.rand(1, num_data_servers); for(int try_times = 0; ; try_times++){ mac_id = (generated_id + try_times) % num_data_servers + 1; auto alloc_res = clients_[mac_id]->call("alloc_block"); if(alloc_res.is_err()) continue; auto resp = alloc_res.unwrap(); auto bv_id = resp->as<std::pair<block_id_t, version_t>>(); block_id = bv_id.first; version_id = bv_id.second; if(!block_id) continue; break; } u64 content_sz = inode_p->get_size(); auto num_block = content_sz / block_size; if(content_sz % block_size != 0) num_block++; inode_p->blocks[num_block * 2] = block_id; inode_p->blocks[num_block * 2 + 1] = (static_cast<u64>(mac_id) << 32) | static_cast<u64>(version_id); inode_p->inner_attr.size += block_size; inode_p->inner_attr.set_all_time(time(0)); auto write_res = bm->write_block(inode_id, inode.data()); fo_mtx.unlock(); if (write_res.is_err()) { return {}; } return {block_id, mac_id, version_id}; }free_block:在Data Server上释放文件的一个块,并在Metadata Server上删除其记录。
Filesystem Client
在src/distributed/client.cc中:
mknode:用给定的类型、名称和父目录创建一个inode。unlink:从其父目录中删除一个文件。lookup:尝试通过其名称和父目录搜索一个inode。readdir:读取目录的内容。get_type_attr:获取inode的类型和属性。read_file:读取文件的内容。write_file:写入文件的内容。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46auto ChfsClient::write_file(inode_id_t id, usize offset, std::vector<u8> data) -> ChfsNullResult { auto get_map_res = metadata_server_->call("get_block_map", id); if(get_map_res.is_err()) return ChfsNullResult(ErrorType::BadResponse); auto get_map_resp = get_map_res.unwrap(); auto block_map = get_map_resp->as<std::vector<BlockInfo>>(); auto num_block = block_map.size(); auto write_sz = 0; auto cur_block = offset / DiskBlockSize; auto cur_offset = offset % DiskBlockSize; usize size = data.size(); while(write_sz < size){ BlockInfo cur_info; if(cur_block < num_block){ cur_info = block_map[cur_block]; } else { auto alloc_res = metadata_server_->call("alloc_block", id); if(alloc_res.is_err()) return ChfsNullResult(ErrorType::BadResponse); auto alloc_resp = alloc_res.unwrap(); cur_info = alloc_resp->as<BlockInfo>(); } block_id_t block_id = std::get<0>(cur_info); mac_id_t mac_id = std::get<1>(cur_info); auto len = std::min(DiskBlockSize - cur_offset, size - write_sz); auto cur_data = std::vector<u8>(data.begin() + write_sz, data.begin() + write_sz + len); auto write_res = data_servers_[mac_id]->call("write_data", block_id, cur_offset, cur_data); if(write_res.is_err()) return ChfsNullResult(ErrorType::BadResponse); auto resp = write_res.unwrap(); auto res = resp->as<bool>(); if(!res) return ChfsNullResult(ErrorType::BadResponse); cur_block++; cur_offset = 0; write_sz += len; } return KNullOk; }free_file_block:释放文件的一个块,并在Metadata Server上删除其记录。
类似于GFS,如果客户端想要读写一个文件,它应该首先从Metadata Server获取块映射(属于该文件的块的块ID)。然后它可以直接向Data Server上的相应块发送读写请求。如果客户端想要写入一个空文件,它应该首先调用Metadata Server在Data Server上分配一个块。
由于这种分离设计,一个棘手的情况是可能会出现before-or-after原子性问题。如果一个客户端首先获取文件A的映射,另一个客户端删除文件A,最后第三个客户端根据文件A的旧映射创建一个新文件,第一个客户端可能会读取错误的数据。因此需要实现一个版本机制来检测这种竞争条件。具体来说,每个块都有一个版本号,该版本号与Data Server上的块一起存储,如下所示。基于版本,Metadata Server还将存储属于文件的块的版本。这些版本将作为映射的一部分返回给客户端。
如果一个块不再属于一个文件,我们将在Data Server上首先增加块的版本。基于这个方案,我们可以通过让Data Server拒绝版本不匹配的块读写请求来检测上述竞争。
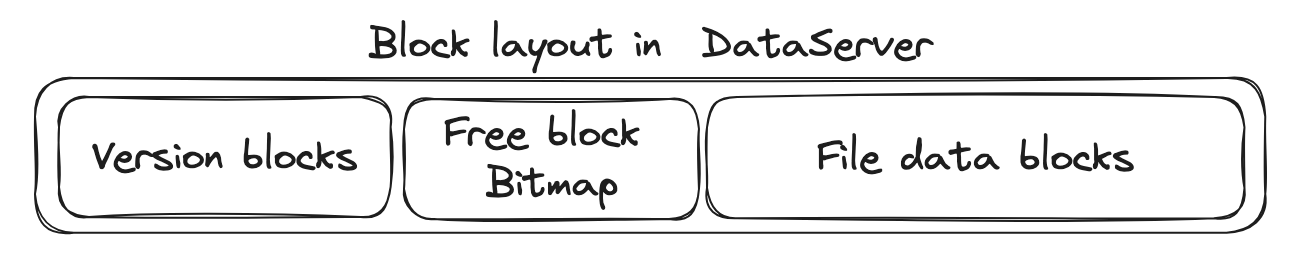
为了实现上述方法,需要完善以下函数的实现:
DataServer::DataServer:在构造函数中添加任何你想要持久化块版本到磁盘的内容。DataServer::read_data:检查版本是否有效。DataServer::alloc_block:分配一个块并更新其版本。DataServer::free_block:释放块并更新其版本。MetadataServer::get_block_map:也将块的版本返回给客户端。MetadataServer::allocate_block:也记录块的版本。
支持并发
为了应对多个线程并发处理客户端的RPC的情况,在系统中添加全局锁(2PL有点搞不明白呜呜),以保持以下这些元数据操作的Before-or-After原子性。
mknodeunlinkallocate_blockfree_block
故障恢复
使用redo日志来确保文件系统元数据操作的all-or-nothing原子性。有以下假设:
- 通过调用
BlockManager::write_block写入磁盘的数据不会立即持久化到磁盘。这些更改会保留在页面缓存中,直到它们被刷新到磁盘。有两个接口用于将数据刷新到磁盘:BlockManager::sync和BlockManager::flush。前者将特定块刷新到磁盘,后者将页面缓存刷新到磁盘。这些调用返回后,数据才会持久化到磁盘。 - 向块写入数据是原子性的。也就是说,如果你向块写入数据,数据将被完全写入或根本不写入。
- 只确保MetadataServer的以下两个操作的原子性:
MetadataServer::mknodeMetadataServer::rmnode
日志管理器
为了简化,只在日志中记录更新的块值。例如,如果创建了一个文件,它将至少更新3个块,因此日志将包含3个新块。
首先,修改BlockManager以支持在磁盘上存储日志,在磁盘上保留1024个块用于持久化日志(假设不会一口气用完这么多块)。现在,块设备上的布局如下:
| |
Log super block存的信息包括:
current_log_id:当前写日志在Log blocks的位置(0 <current_log_id< 1024)log_block_cnt:当前写了多少Log block(好像没啥用)current_txn_id:当前的事务的id,由于全局锁,一次最多就有一个事务在工作,这简化了一些麻烦。txn_entry_cnt:TxnEntry的数量
Transaction table里的每一个元素是一个TxnEntry,Log table里的每一个元素是一个ActionEntry。
| |
一个Action其实就对应一次write_block,ActionEntry的:
block_id记录着这次write_block改动的block的idlog_block_id记录着这次write_block对应的Log block的id- 这个Log block的内容就是这次
write_block的内容(不管是不是partial,都把整个block记下来)
这样一来,当我要重做这个action的时候,把log_block_id对应block的内容copy到block_id对应的block即可。
每个事务其实是用类似链表的结构串起每个Action(table_offset就是下一个ActionEntry在Log table中的位置,充当指针的角色)。
每一次调用write_block,都会同时写下日志,将日志刷新到磁盘。
然后,在src/distributed/commit_log.cc中:
alloc_txn:开启一个新的事务。修改的是| Log super block | Transaction table |。
在src/include/distributed/metadata_server.h中:
recover:从磁盘读取块值的变化,并重做操作以实现all-or-nothing的原子性。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20auto recover() -> void { BlockManager *bm = this->operation_->block_manager_.get(); std::vector<u16> log_super_block(bm->block_sz); memcpy(log_super_block.data(), bm->block_data + bm->block_cnt * bm->block_sz, bm->block_sz); auto super_block = reinterpret_cast<SuperLogBlock *>(log_super_block.data()); u16 txn_entry_cnt = super_block->txn_entry_cnt; for (u16 i = 0; i < txn_entry_cnt; i++) { TxnEntry txn_entry; memcpy(&txn_entry, bm->block_data + (bm->block_cnt + LogBlockCntWoTxn) * bm->block_sz + i * sizeof(TxnEntry), sizeof(TxnEntry)); if (txn_entry.is_committed != true) { if (txn_entry.txn_type == TxnType::MKNODE) { const std::string name(txn_entry.name); mknode(txn_entry.type, txn_entry.parent, name); } else if (txn_entry.txn_type == TxnType::UNLINK) { const std::string name(txn_entry.name); unlink(txn_entry.parent, name); } } } }
嘶,前面搞了半天什么log block,recover的时候好像完全没用上?实际上是因为我在实现完前面一大堆之后才开始实现recover,然后发现其实根本不用那么麻烦……用log block的方法相当于物理日志(记录block的具体变化),直接在TxnEntry里记录操作信息就有点像逻辑日志。理论上说redo日志应该使用物理日志(因为要求幂等性),不过这里因为mknode和rmnode这两个操作本身就是幂等的,所以物理日志和逻辑日志都没有问题。
checkpoint
存储日志可能会占用大量磁盘空间,需要实现检查点以减少日志大小。在src/distributed/commit_log.cc中:
commit_log:标记一个事务为完成。checkpoint:将所有完成的事务的TxnEntry丢弃。get_log_entry_num:返回磁盘中的日志条目数量。
Raft
介绍
Raft 是一种用于复制日志的共识算法。Raft将共识问题分解为相对独立的子问题,这些子问题更容易理解。 Raft中的关键数据结构是log,它将客户端的请求组织成一个序列。 Raft保证所有服务器将以相同的顺序应用相同的日志命令,这意味着服务器都将处于一致的状态。 如果服务器失败但后来恢复,Raft会负责将其日志更新到最新状态。 只要至少有大多数服务器处于活动状态并且连接,Raft就可以工作。
Raft通过首先在服务器之间选举一个leader来实现共识,然后赋予leader管理和管理日志的权限和责任。leader接受客户端的日志条目(log entry),在其他服务器上复制它们,并告诉服务器何时可以安全地将日志条目应用到它们的状态机上。日志应该持久化,以容忍机器崩溃。随着日志的增长,Raft将通过快照(snapshot)来压缩日志。
Raft论文的完整版本。论文中的图2和图13可以涵盖本项目中的大部分设计。
代码概览
相关代码主要集中在src/include/rsm/raft/node.h, src/include/rsm/raft/log.h, src/include/rsm/raft/protocol.h。
有以下几个重要的C++类。
ChfsCommand
src/include/rsm/state_machine.h中的ChfsCommand类与状态机相关。当状态机追加或应用日志时,将使用ChfsCommand。状态机处理来自日志的相同序列的ChfsCommand,因此它们产生相同的输出。ChfsCommand提供serialize和deserialize方法。
ChfsStateMachine
src/include/rsm/state_machine.h中的ChfsStateMachine类表示Raft中的复制状态机。
| |
RaftLogEntry
| |
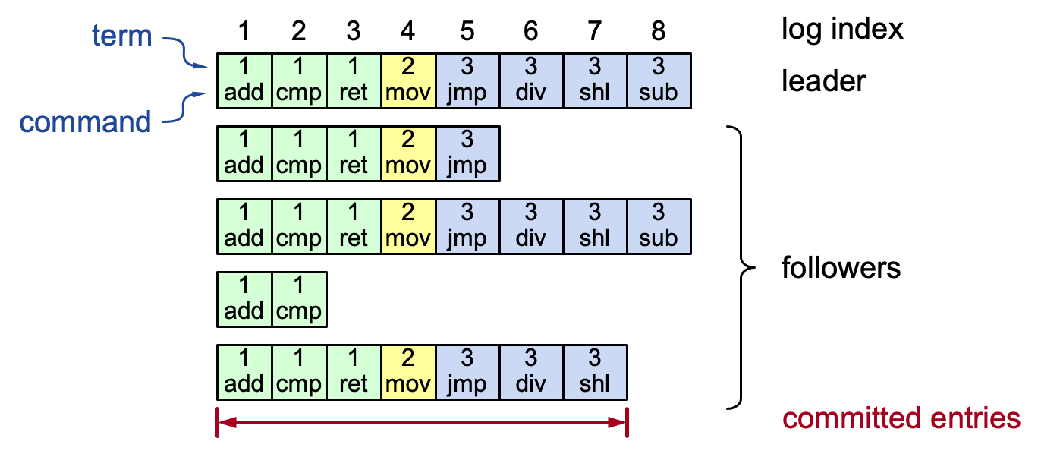
RaftNode
src/include/rsm/raft/node.h中的RaftNode类表示一个Raft节点(或Raft服务器)。RaftNode是一个带有两个模板参数StateMachine和Command的类模板,意味着它将共识算法与状态机解耦。
Raft算法是异步实现的,这意味着事件(例如leader选举或日志复制)都应该在后台发生。RaftNode 在调用 RaftNode::start() 后启动,并将创建4个后台线程。后台线程将在后台定期执行某些操作(例如在 run_background_ping 中发送心跳,或在 run_background_election 中开始选举),后台线程在每次循环迭代后睡眠一段时间,而不是一直等事件。
除了事件,RaftNode 之间的RPC也应该异步发送和处理,使用线程池(ThreadPool)来处理异步事件。
在node.h中有RAFT_LOG和DEBUG_LOG宏,将RaftNode中的debug_log_enabled设为true即可生成日志。
RaftLog
用RaftLog以持久化Raft日志和元数据。可以使用ChfsCommand提供的接口来实现日志持久化。
序列化与反序列化
LibRPC 提供了 MSGPACK_DEFINE 来自动在RPC调用中序列化和反序列化自定义数据结构。例:
| |
在使用 MSGPACK_DEFINE 之前,需要手动将自定义数据结构中的模板类型转换为基本类型。
一致性与安全性
A log is committed if it can be safely applied to the state machine.
High level of coherency(一致性) between logs maintained by the raft: If log entries on different servers have the same index & term:
- They store the same command
- The logs are identical in all preceding entries
If a given entry is committed, all preceding entries are also committed.
Overwrite can ensure consistency. But it makes a subtle issue:When can we commit a log entry? (Since an appended log entry may be overwritten)
Raft safety property: If a leader has decided that a log entry is committed, that entry will be present in the logs of all future leaders (no overwritten).
To ensure safety property:
During elections, choose candidate with log most likely to contain all committed entries. Voting server V denies vote if its log is “more complete”:
(lastTermV > lastTermC) ||(lastTermV == lastTermC) && (lastIndexV > lastIndexC)For a leader to decide an (previous) entry is committed:
Must be stored on a majority of servers
At least one new entry from leader’s term must also be stored on majority of servers
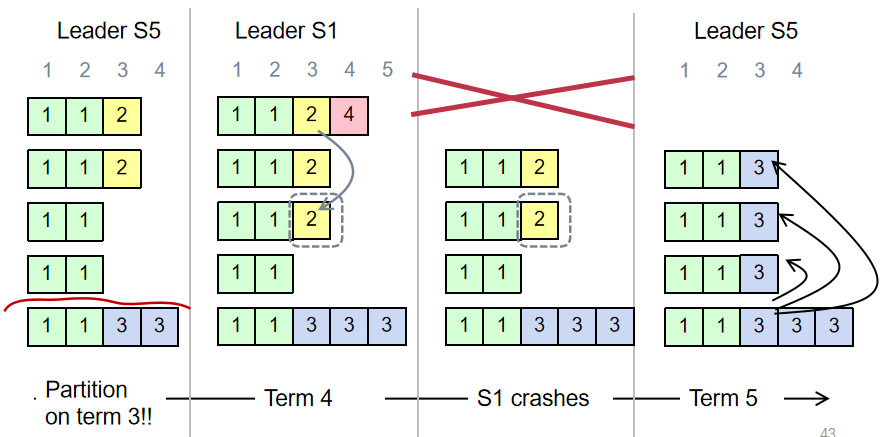
Leader Election & Heartbeat
主要涉及:
protocol.h中的RequestVoteArgs和RequestVoteReply类。node.h中的:RaftNode::request_vote:发起投票RaftNode::handle_request_vote_reply:回复投票RaftNode::run_background_election:在leader超时后将节点转换为candidate,并异步发送request_voteRPC开始选举。
为了保持领导地位,leader应该定期向follower发送心跳(即一个空的AppendEntries RPC)。通过实现AppendEntries RPC来实现心跳。
- 在
protocol.h中的AppendEntriesArgs、AppendEntriesReply - 在
node.h中的RaftNode::append_entries、RaftNode::handle_append_entries_reply、RaftNode::run_background_ping
一些注意事项:
- 为确保不同节点的选举超时不会总是同时发生,每个节点的timeout在一定范围内随机。
- 在所有事件的开头使用
std::unique_lock<std::mutex> lock(mtx);以避免并发错误。 - 在访问RPC客户端指针之前检查空指针。
Log Replication
在node.h中:
RaftNode::new_command:将新命令追加到leader的日志中。- 完成与
AppendEntriesRPC相关的方法 RaftNode::run_background_commit:异步将日志发送给follower。RaftNode::run_background_apply:将提交的日志应用到状态机。
一些注意事项:
第一个日志索引是1而不是0。为了简化编程,在日志的最开始追加一个空的日志条目。由于
lastApplied索引从0开始,第一个空的日志条目永远不会被应用到状态机。nextIndex的作用: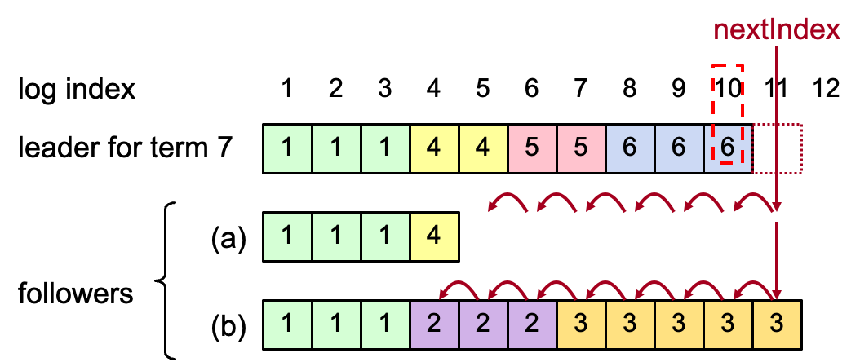
Log Persistency
在log.h中实现RaftLog类。在RaftNode中创建RaftLog对象。每个Raft节点将有自己的日志来持久化状态。并且在故障后或者节点被创建时,节点将通过日志恢复。日志存储在/tmp/raft_log下。
| |
| |
假设Raft日志的总大小总是小于64K,单个日志条目的大小总是小于4K。不考虑磁盘I/O期间的崩溃。
Snapshot
主要涉及:
protocol.h中的InstallSnapshotArgs和InstallSnapshotReply类。RaftNode::install_snapshot:发送snapshot。RaftNode::handle_install_snapshot_reply:接受并应用snapshot。RaftNode::save_snapshot:将snapshot应用到日志中。- 修改之前实现的所有与日志相关的代码。现在需要使用两个概念来表示日志索引:物理索引(例如
std::vector的索引)和逻辑索引(物理索引+快照索引)。 - 在
RaftNode构造函数中恢复快照。
Map Reduce
概览
基于前面实现的分布式文件系统构建一个MapReduce框架。实现一个调用Map和Reduce函数并处理读写文件的worker进程,以及一个coordinator进程,该进程将任务分配给worker进程并处理失败的worker进程。
可以参考MapReduce论文以获取更多详细信息。
新增文件:
src/include/map_reduce/protocol.h:定义了本实验中所需的基本数据结构和接口src/map_reduce/basic_mr.cc:基本Map函数和Reduce函数的实现src/map_reduce/mr_sequential.cc:顺序MapReduce的实现src/map_reduce/mr_coordinator.cc:coordinator的实现src/map_reduce/mr_worker.cc:worker的实现
测试
| |
测试所需的文件预先存储在分布式文件系统中。例如,获取名为being_ernest.txt的文件的文件描述符:
| |
Mapper & Reducer
在src/map_reduce/basic_mr.cc中实现Word Count的Mapper和Reducer。
| |
Sequential MapReduce
在src/map_reduce/mr_sequential.cc中的主干逻辑,在单个进程中依次运行Map和Reduce。
| |
(这里当时为了通过那个要求并行不能慢于串行的三倍的测试,反向优化了串行,多写了一些没必要写的文件)
Distributed MapReduce
分布式MapReduce包括两个程序,mr_coordinator.cc和mr_worker.cc。
只有一个coordinator,但一个或多个worker并发执行。worker通过RPC与coordinator通信。每个worker将向coordinator请求一个任务,从一个或多个文件中读取任务的输入,执行任务,并将任务的输出写入一个或多个文件,然后向coordinator提交任务以提示完成。
coordinator的基本循环如下:首先分配Map任务;当所有Map任务完成后,然后分配Reduce任务;当所有Reduce任务完成后,Done()循环返回true,表示所有任务完全完成。
coordinator需要注意,如果worker在合理的时间内未完成其任务,将相同的任务分配给不同的worker(这个逻辑以前是有的,为了通过作业的测试反而删掉了)
worker有时需要等待,例如Reduce任务在最后一个Map任务完成之前不能开始。如果coordinator告知让worker等待,worker将睡眠一小段时间。